TL;DR: We use physics-based optimization to reconstruct scenes and grasp unseen objects zero-shot from a single RGBD image, with no 3D training data.
Abstract
Operating effectively in novel real-world environments requires robotic systems to estimate and interact with previously unseen objects.
Current state-of-the-art models address this challenge by using large amounts of training data and test-time samples to build black-box scene representations.
In this work, we introduce a differentiable neuro-graphics model that combines neural foundation models with physics-based differentiable rendering to perform zero-shot scene reconstruction and robot grasping without relying on any additional 3D data or test-time samples.
Our model solves a series of constrained optimization problems to estimate physically consistent scene parameters, such as meshes, lighting conditions, material properties, and 6D poses of previously unseen objects from a single RGBD image and bounding boxes.
We evaluated our approach on standard model-free few-shot benchmarks and demonstrated that it outperforms existing algorithms for model-free few-shot pose estimation.
Furthermore, we validated the accuracy of our scene reconstructions by applying our algorithm to a zero-shot grasping task.
By enabling zero-shot, physically-consistent scene reconstruction and grasping without reliance on extensive datasets or test-time sampling, our approach offers a pathway towards more data efficient, interpretable and generalizable robot autonomy in novel environments.
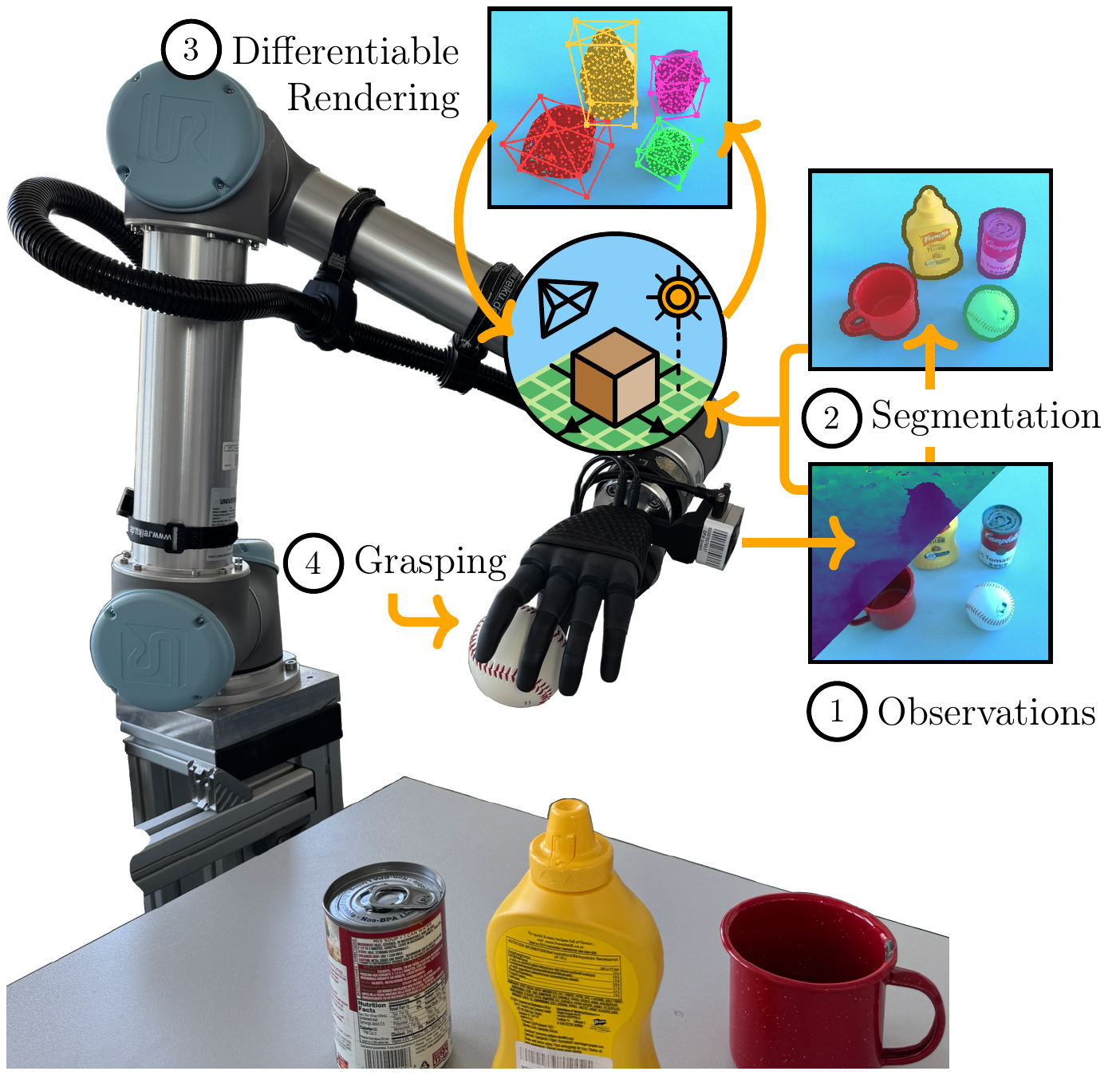
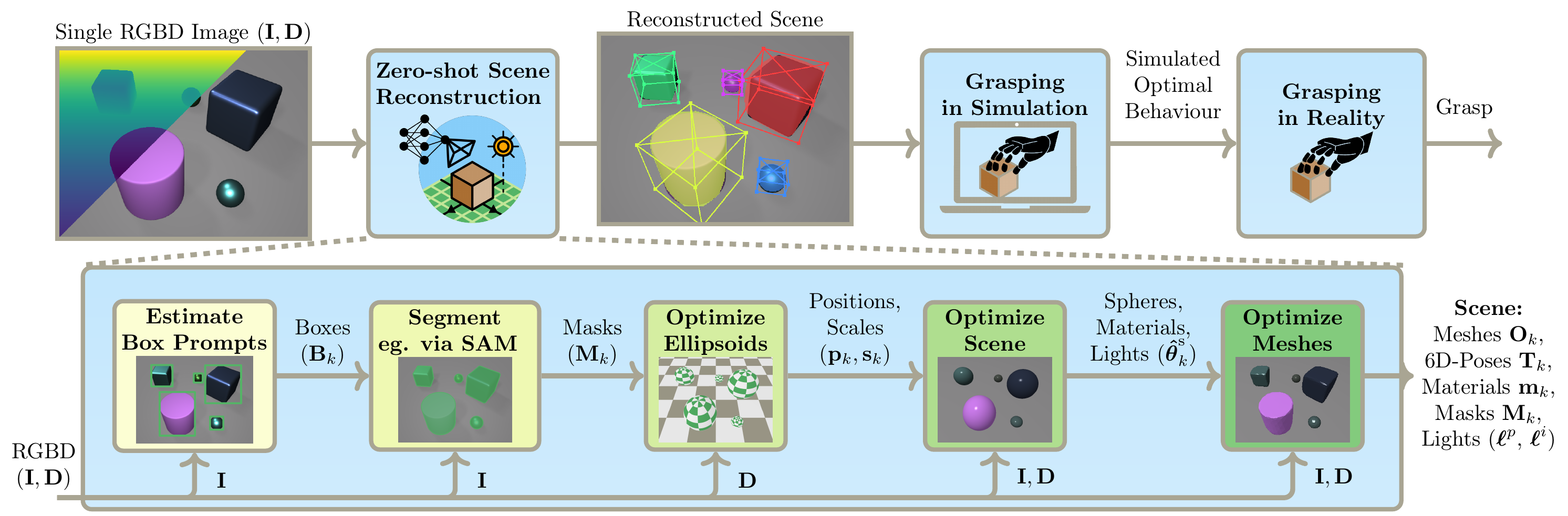
Global Pipeline
From a single RGBD image and bounding box prompts, our model uses a segmentation model to estimate the object masks. It then initializes a 3D scene by performing a robust probabilistic estimation of object shapes using ellipsoidal primitives. Subsequently, it optimizes the shapes, poses, materials, and lighting conditions with physics-based differentiable rendering by matching rendered views to the real observation. A final mesh optimization stage refines the mesh vertices through a cage-based deformation model.
Finally, the reconstructed scene is used in simulation to find an optimal grasp, which is then performed in reality using the robotic system
The resulting scene representation includes meshes, poses, materials, masks, and lighting conditions.
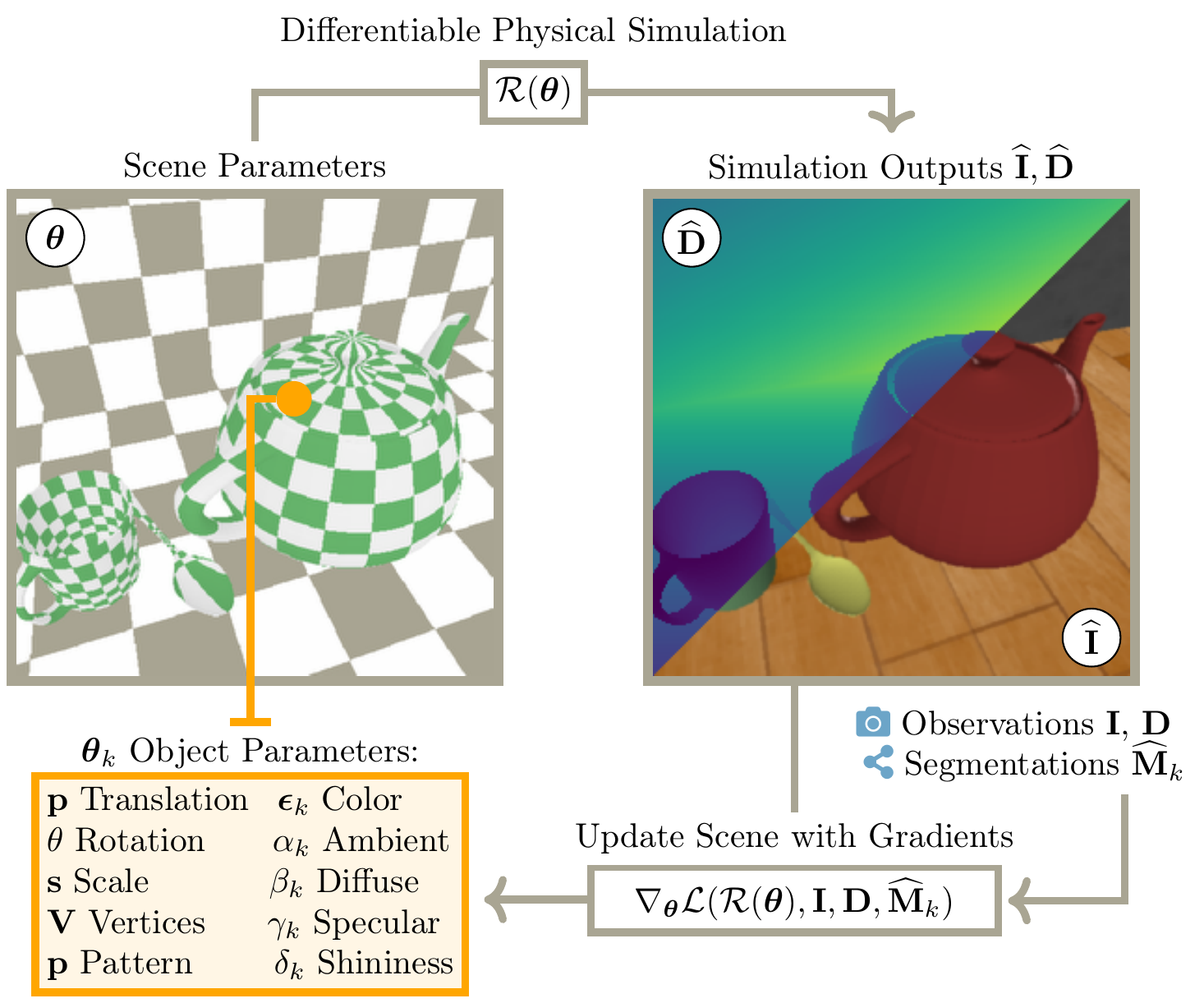
Differentiable Rendering
The renderer compares rendered RGBD observations against
the real input and provides gradients for optimizing
scene parameters. This is the core mechanism that turns
the reconstruction problem into an explicit inverse
optimization problem rather than a black-box prediction.
Physical scene variables: Optimization acts on
interpretable quantities such as object pose, shape,
materials, and lighting, rather than latent features.
Scene-to-image rendering: The renderer maps
these interpretable parameters into rendered RGB,
depth, and mask estimates.
Inverse graphics formulation: Reconstruction is
posed as finding the scene parameters whose rendered
appearance best explains the observed image.
Gradient-based refinement: The mismatch between
rendered and real observations is backpropagated to
update the scene parameters directly.
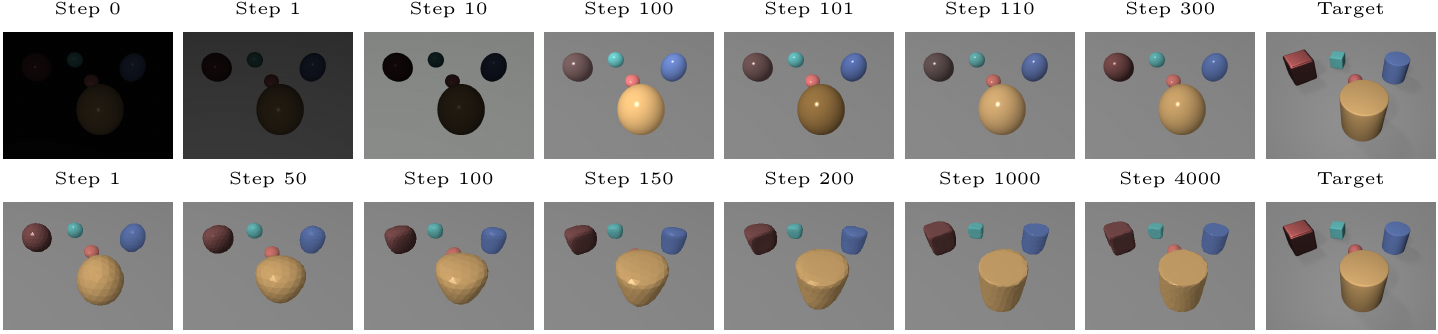
Inverse Optimization
The reconstruction is solved as a sequential optimization pipeline. The first stage (top-row) optimizes simple spherical object representations together with lighting, materials, and object layout so that the rendered scene matches the observed RGBD image. The second stage (bottom-row) replaces those simple shapes with triangular meshes and refines their geometry through a cage-based deformation model using mean value coordinates. This lets the system preserve the scene structure found in the first stage while optimizing more detailed object shapes that better explain the observation.
Results
The qualitative results evaluate FewSOL, CLEVR-POSE, MOPED, and LINEMOD-OCCLUDED, demonstrating zero-shot generalization to previously unseen objects. Despite changes in shape, texture, material, clutter, and occlusion, the method recovers consistent object pose and geometry across these datasets.
Videos
Shape optimization for CLEVRPOSE concept 030.
Mesh optimization for CLEVRPOSE concept 030.
Optimized mesh orbit for CLEVRPOSE concept 030.
Robot Grasping
The reconstructed scene is used to evaluate candidate
grasps in simulation and then execute the best grasp on
the robot with the UR5 arm, Mia hand, and D405 camera.
Zero-shot grasping: The perception pipeline
enables grasping unseen objects without CAD models, grasp-specific
training data or additional 3D supervision.
Broad evaluation: We ran 224 real-world grasp
trials across 10 diverse YCB objects varying in size, weight, transparency, and symmetry.
Strong transfer: Using a very simple grasping policy the system achieved an 89.3% overall grasp success rate on the physical robot.
BibTeX
@misc{arriaga2026differentiable,
title={Differentiable Inverse Graphics for Zero-shot Scene Reconstruction and Robot Grasping},
author={Arriaga, Octavio and Sharma, Proneet and Guo, Jichen and Otto, Marc and Kadwe, Siddhant and Adam, Rebecca},
year={2026},
eprint={2602.05029},
archivePrefix={arXiv},
primaryClass={cs.RO},
doi={10.48550/arXiv.2602.05029},
url={https://arxiv.org/abs/2602.05029}
}